Summarizing viral videos with local AI models
a search engine for video memes
📅 july 2024
This post describes a side project leveraging VILA, Llama 3, and Whisper to generate local (e.g. on my home computer) summaries of social media videos. The resulting metadata was then indexed into a local instance of meilisearch.
Here's a video of the project:
background
It's mid-2024, and generative AI remains in fashion - GPTs are being integrated into applications at a dizzying rate. Last year, someone even tried a ChatGPT-led church service.
I like to experiment with local/downloadable models - these can be freely run on consumer machines and the data stays on-device.
Earlier this year, Meta released Llama 3. NVIDIA and MIT also released VILA, a visual language model. I wanted to try them - so like many software endeavors, I picked the tech first and looked for a adjacent problem afterwards. 🙂 I tried local summarization of my favorite social media videos. Then I ingested them to a meilisearch instance for proof-of-concept search.
Most of this took place in early May - I remember GPT-4o was released the week after.
example summary
Here's what the full pipeline produced on this adorable video.
Transcription (via Whisper)
I can mention that you poop without warning so keep an arm in the hand distance that baby face won't help you
Even if you had a grand entrance since I'm giving you bars
That means your new name is San Quentin
You messing with me?
Yo, get your mans, bro.
Get your...
Get your mans.
Get your mans, yo.
Wow, get your mans.
Yo.
What's your life like, Quentin?
Nah, nah, nah.
What's your life like, Quentin?
What's your life like, Quentin? Nah, nah, nah. What's your life like, Quentin? What's your life like, Quentin?
Every day you get pocket checked.
You eat like a king.
Two pair of households.
And you get lots of rest.
Yo, you're not a threat.
Get your mans, bro.
Get your mans, bro.
You can't come at me with gangster talk.
You can't come at me with gangsta talk.
You can't come at me with gangsta talk.
Claiming you poppin' tech.
I bag your mom.
I tell you when to go to sleep.
I don't have any losses yet.
Bro, what's so funny, bro?
This is strictly tech.
You thought you would take me on?
...
Analysis (via Whisper / Llama 3 / VILA)
The context is a rap battle between the adult (Quentin) and the baby (Beto). The adult uses baby talk and slang to engage in a playful battle, while the baby responds with coos and laughter. Subtitles suggest that the adult is poking fun at the idea of a baby being a rival in a rap battle.
Key moments include references by the adult to the baby's diaper changes, sleep patterns, and perceived lack of threats. The baby responds with coos and laughter, while the adult continues to engage in the rap battle.
The overall tone of the video is playful and lighthearted, with the adult using humor and wordplay to engage in a fun battle with the baby.
model overview
This section describes the three models.
VILA (encodes visual info for LLM)
VILA is among a growing family of visual language models released by NVIDIA and MIT. Some VILA/TinyChat demos are reproduced below:
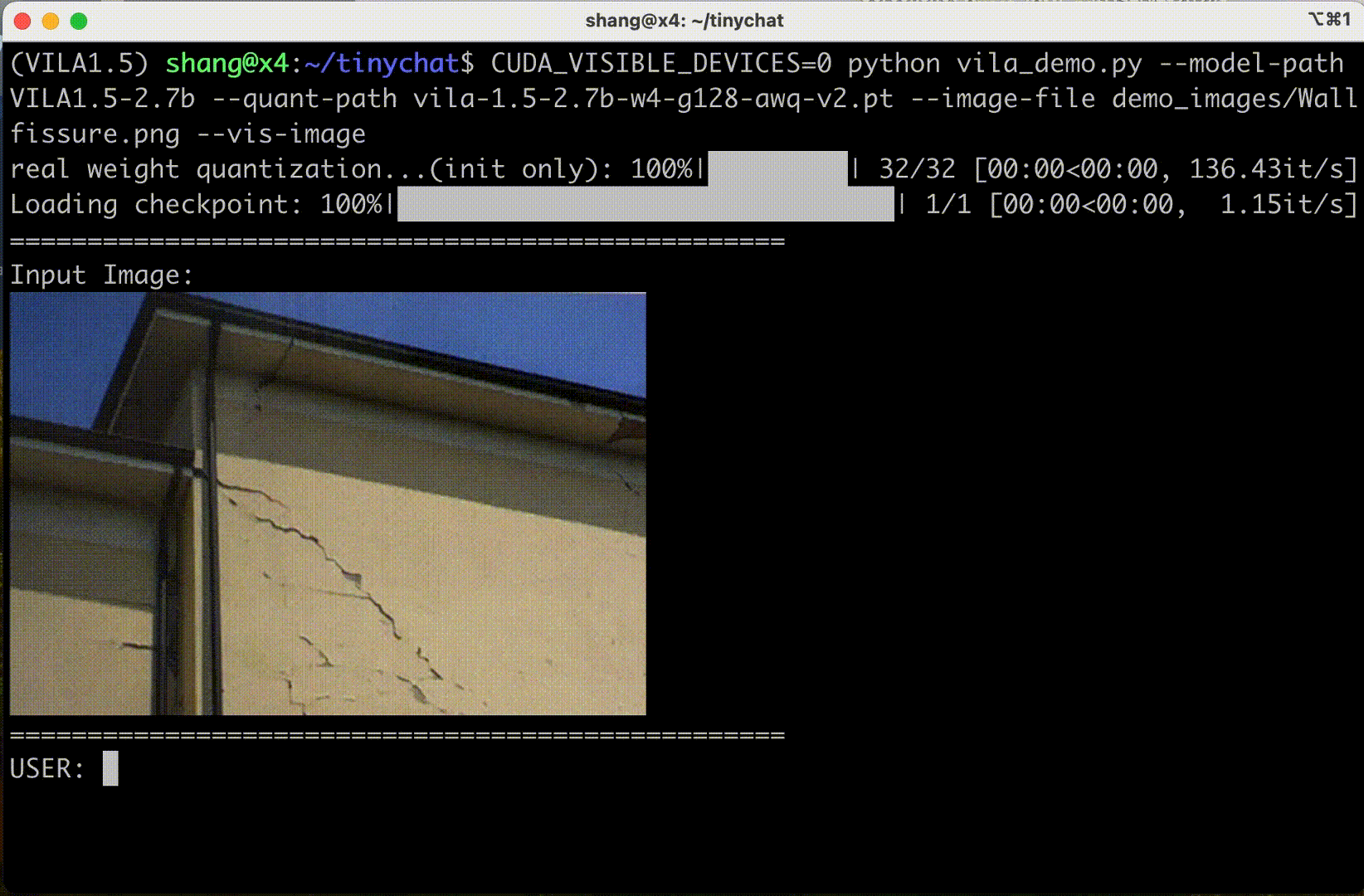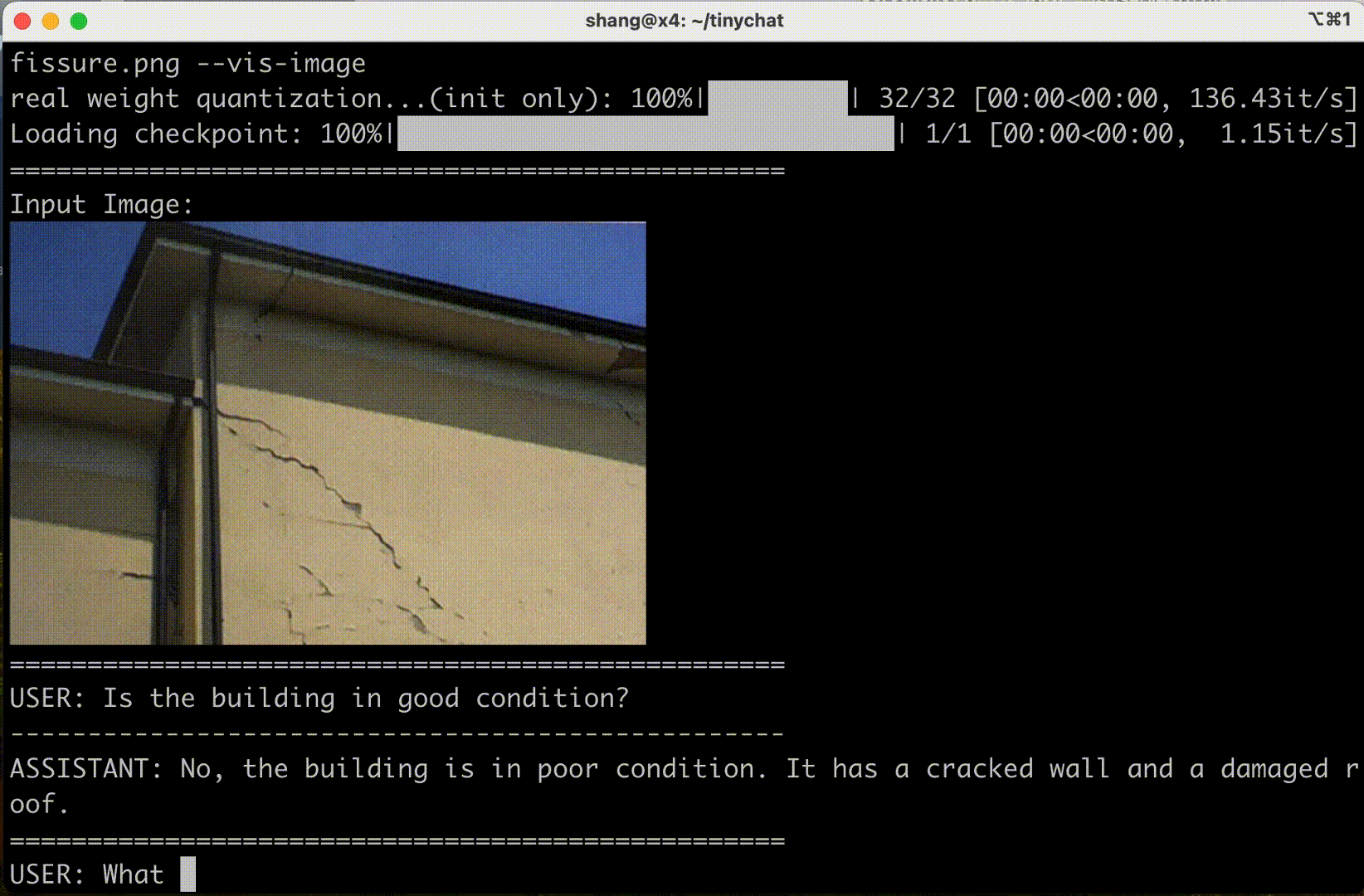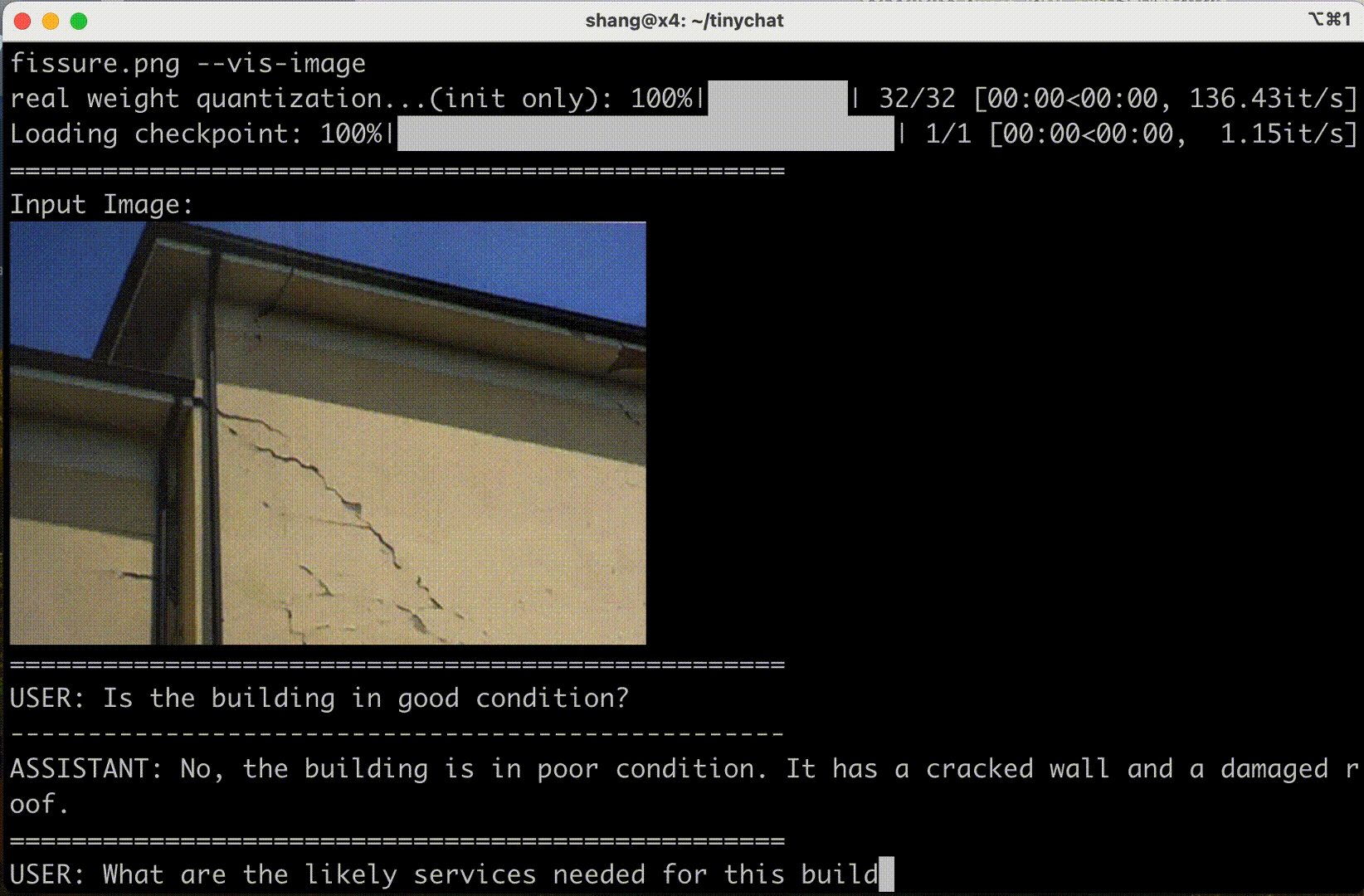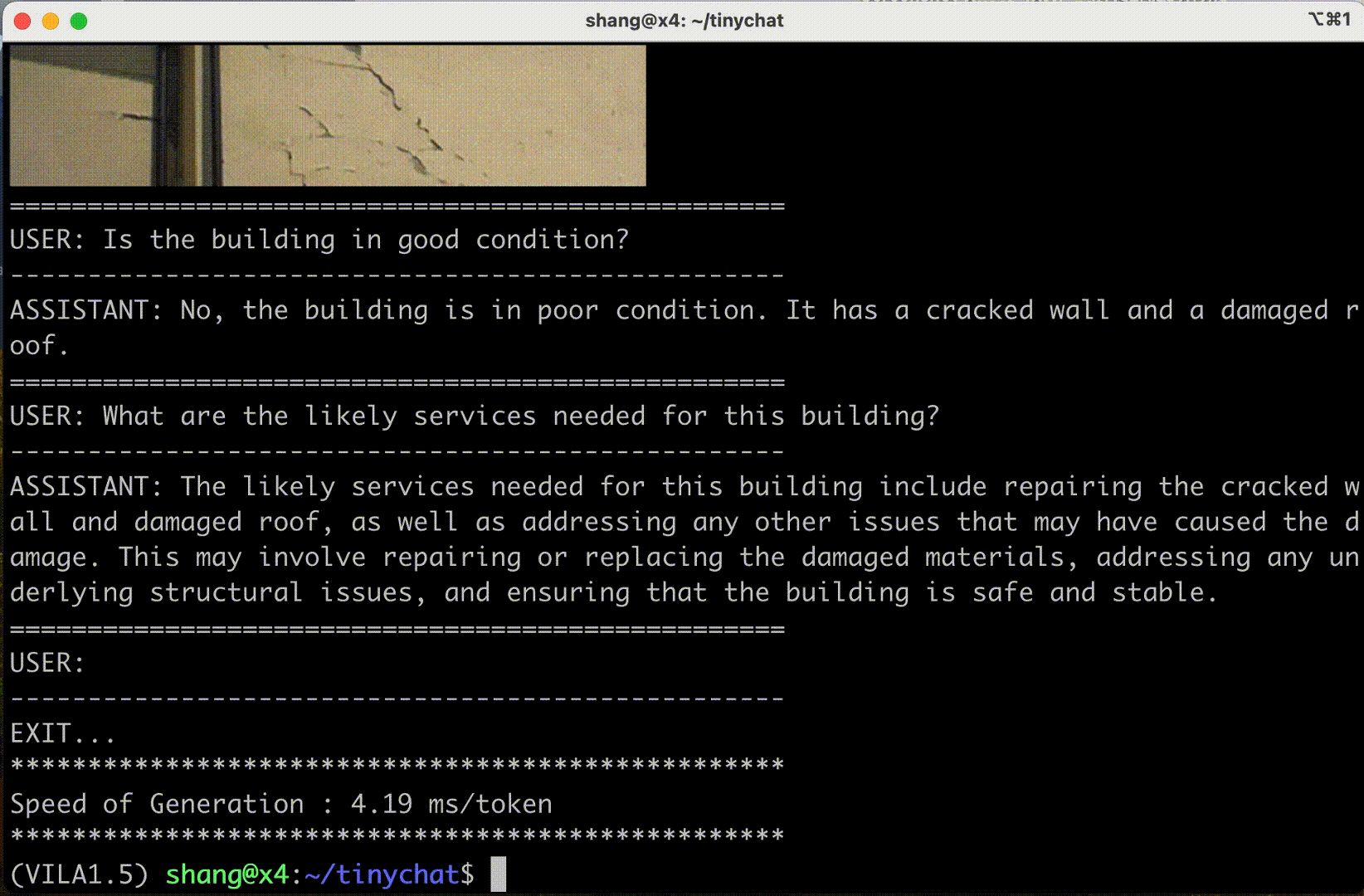
VILA also supports input frame sequences (and therefore video). Their demo below shows three frames in sequence:
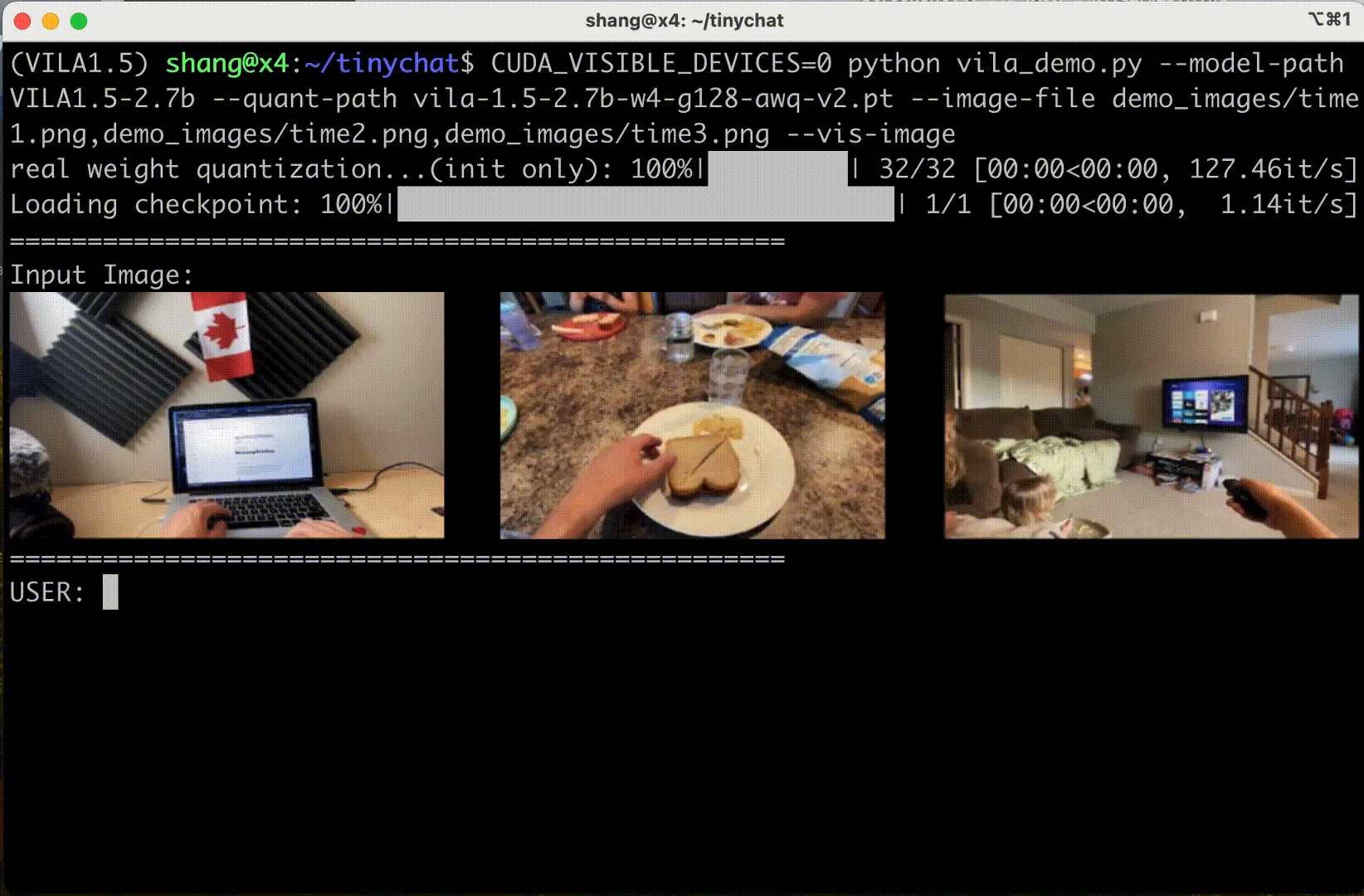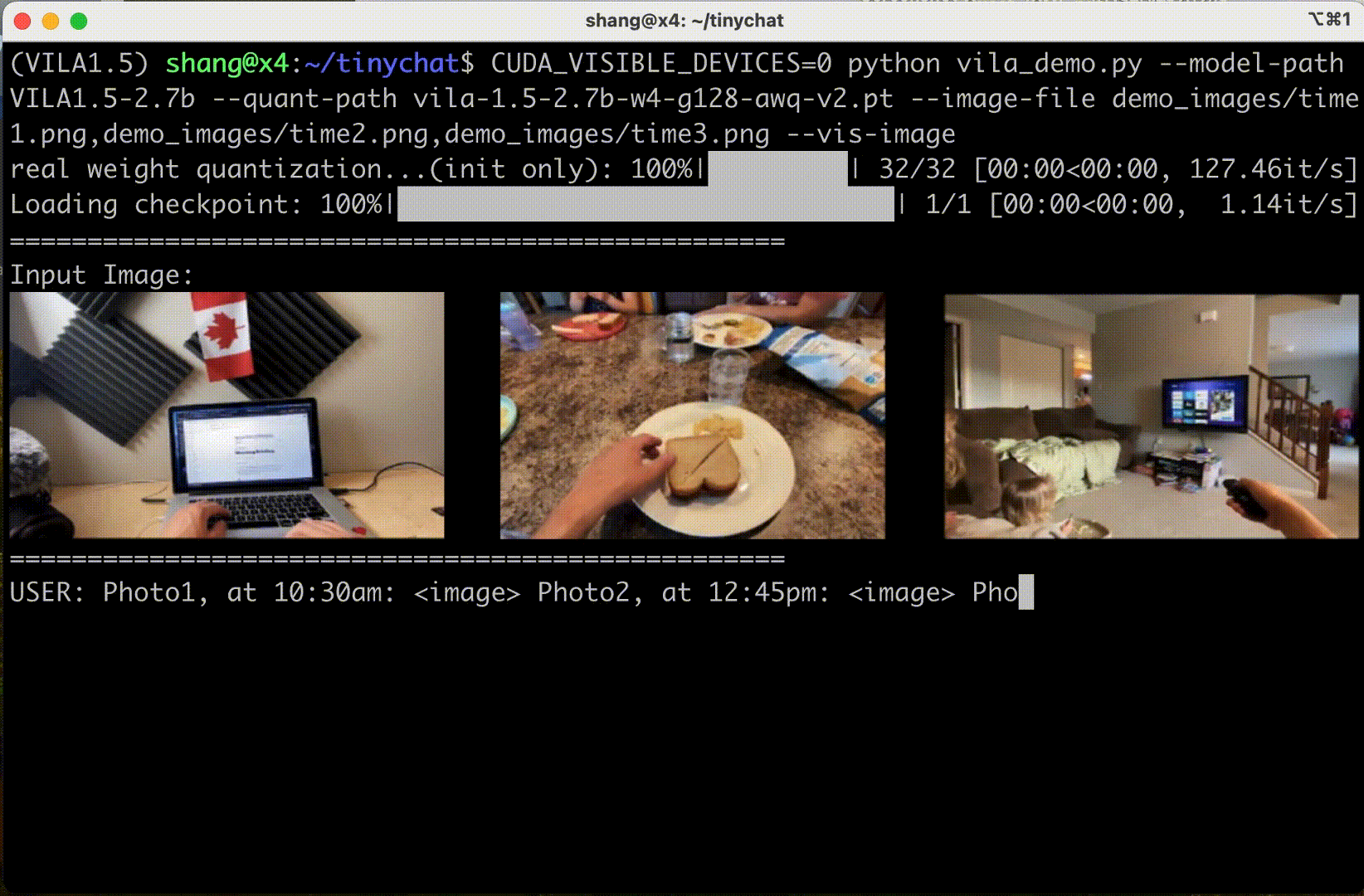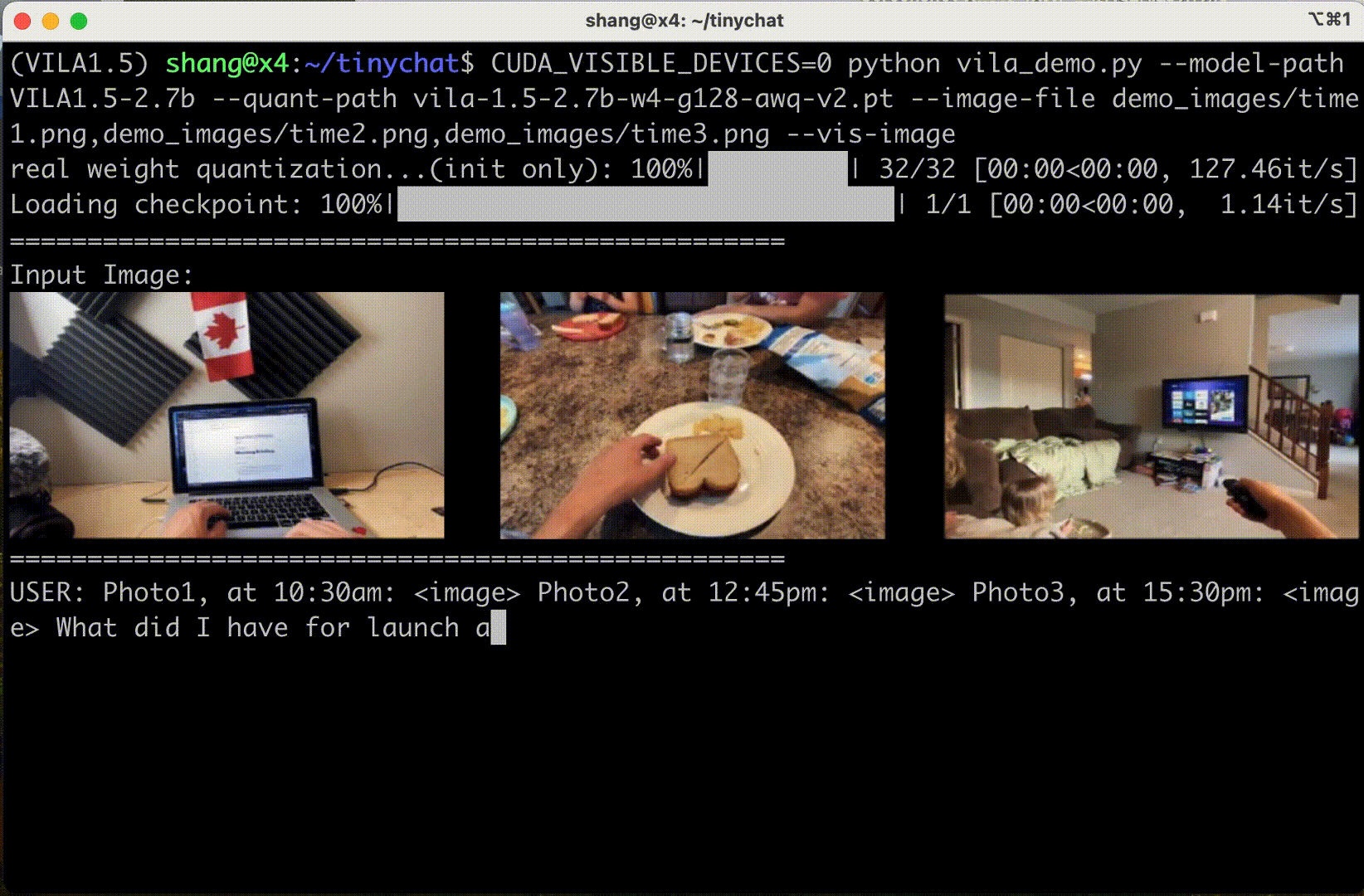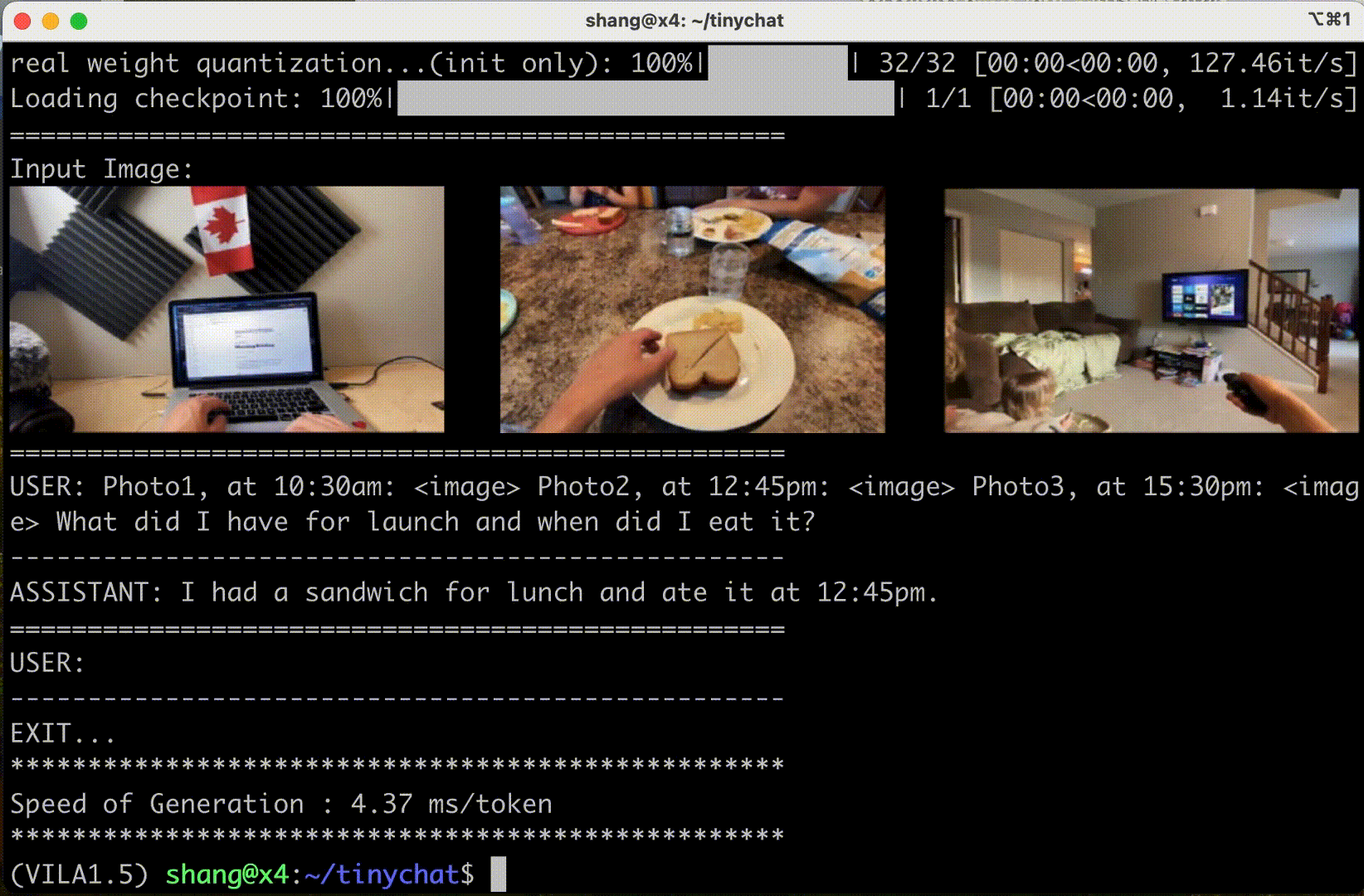
NVIDIA enabled AWQ 4-bit quantization. Coupled with TinyChat inference, it means VILA can run on RTX GPUs - engineers looking to experiment with deep learning or AI at home often get NVIDIA GeForce RTX 3090s or 4090s. I used Efficient-Large-Model/Llama-3-VILA1.5-8B.
Llama 3 (large language model)
This is Meta's large language model - you can find the model card here. As of this week, Meta has just released Llama 3.1. Ollama is an easy way to experiment with LLMs; it also offers a python library for scripting. I used the 8b variant.
Whisper (speech to text model)
This is OpenAI's automatic speech recognition model. I used whisper-large-v3 and followed the snippet from insanely-fast-whisper to leverage FlashAttention.
generating summaries
setting a baseline
I tried VILA 'out of the box' against some example videos. It took some time to get setup locally. I ended up switching to wsl. Then I followed these steps from the tinychat repository. I modified the driver code here. The suggested prompt is "Elaborate on the visual and narrative elements of the video in detail" (reference gradio code). On example videos, I learned the following:
- VILA usage uniformly samples 8 frames from each input video (reference code and GH issue). So as-is, some scenes from longer videos can be missed.
- VILA operates on static images; so as expected, sound from the videos is not leveraged. Visually active videos like a soccer match were summarized quite well. But some dialogue-heavy videos (imagine a motivational speech with scenic pictures) suffered from the missing audio.
- Some videos had text on screen, e.g a caption or a shirt logo. Occassionally, VILA was able to include the text contents in its summary.
The baseline was reasonable, so I explored two updates:
- Include more frames from longer videos
- Include information from audio in the summary
long videos
The summaries were effective with up to eight frames. I decided to take one frame per second. This meant each video would be split into eight-second segments. I ran each segment through VILA separately to get an individual summary. For many videos these summaries were similar; but for fast-changing videos, the extra granularity provided extra context. I combined adjacent summaries in a later step. Here's a diagram of the process:

Here's a real-time video of summary generation. You can see adjacent segment summaries are concatenated into arrays for later processing.
using audio
For commentary-heavy videos, the audio was critical. I decided to transcribe using OpenAI's Whisper and place the resulting text alongside the VILA visual summaries for post-processing. My code looked something like this. Whisper worked fairly well overall, with the following notes:
- I took a brief detour into speaker diarisation. When the audio contained fast-moving conversation between two people, the transcription alone did not capture the full context. I tried some libraries but did not see confident results, so I let it go.
- Occassionally, the transcriptions were unclear. This was most common for non-English audio; while Whisper has decent support for major languages, Punjabi videos in particular had mixed results.
Consolidating adjacent summaries
At this point, I had the following data for each video:
- VILA visual summaries: an array of strings, each describing consecutive 8-second segments
- A transcription covering the full video
Adjacent summaries were highly redundant for homogenous videos, and the transcription spanned different segments. So I used Llama 3 in isolation to create a holistic summary reflecting the important parts of the video. I used the Ollama Python library.
First, I tried the naive approach of providing Llama 3 with a single "do-everything" prompt - e.g. remove redundant information from adjacent segment summaries, leverage the transcription, and create an overall description of the video. Understandably, this was a lot of information and didn't work very well. The varied transcription relevance would sometimes overshadow the video input. I tried a few different approaches and landed on the following prompt orchestration:
| Role | Prompt or response |
|---|---|
| USER |
I am watching a video in 8-second increments and summarizing it. You have two jobs:
|
| ASSISTANT | response |
| USER | summary 1 of n |
| ASSISTANT | initial summary |
| USER | summary 2 of n |
| ASSISTANT | updated summary |
| and so on... | |
| USER | summary n of n |
| ASSISTANT | updated summary |
| USER | That was the last one. Please consolidate your findings. |
| ASSISTANT | consolidated summary |
| USER |
I also tried transcribing this video, but there might be mistakes. I will give you the transcription in case it helps to contextualize your earlier analysis, but do not change too much. Please re-state or slightly update your findings.
provided transcription |
| ASSISTANT | final summary |
The above orchestration generally produces a reasonable consolidated summary that takes the transcription into account. I noticed the style was varied; sometimes the LLM produced first-person text. I again asked Llama 3 to massage the text, but this time with fresh history (e.g. new agent / no memory of previous conversation):
| Role | Prompt or response |
|---|---|
| USER |
The following video summary was generated by AI. Remove any language where the AI is speaking in first-person or meta-describing its analysis process. Preface your writing with 'ANALYSIS:'
provided summary |
| ASSISTANT | response |
Function calling or more stringent formatting would be better, but this worked well enough.
indexing
Now I had a consolidated summary and full transcription for each video. To make the metadata searchable, I used meilisearch to locally index and visualize the summaries. I followed the quick start docs and modeled my metadata after their movies.json. I slightly customized their built-in search preview and got things running on localhost. The full-text search is not as sophisticated as other alternatives, but worked well for a proof-of-concept.
odds and ends
If you liked this, I also recommend I accidentally built a meme search engine by Harper Reed. It focuses on static images and is a great read. I tried running some thumbnails through CLIP and saw similar results.
If I had more time, I might try these other ideas:
- Generating text/CLIP embeddings for the summaries & thumbnails for semantic search or RAG patterns
- Trying newly-released Llama 3.1
- Exploring different models from the MMMU leaderboard, or that can process audio & video together
- OCR on adjacent video frames
There are likely better ways to solve this problem from first principles - but this project was a nice way for me to locally experiment with these models.
Thanks for reading! You can find other posts and contact info here.